

The Illusion of Authority in AI is Just Average Answer Dominance
What we currently call “Established Authority” as the reason that big brands get cited by AI is often just “Average Answer Dominance.” People advise fellow colleagues to examine what kind of content gets cited and do whatever they did. If its press release quotes, then do PR. If its listicles, then write listicles.
But the unaddressed aspect to that is that these massive enterprise domains are being cited not because their content logic is “sharp,” but rather because the rest of the web has a signal that is so “muddy” the AI had no choice but to play it safe.
In reality, LLMs default to the most common, average answer from the big brands simply because they can’t find enough structural logic proof to justify trusting anyone else.
Reverse Engineering the Noise In Search
For decades, the standard SEO playbook has been: “See who is winning, and do what they do.” It’s how I started my SEO career doing that with a secure data erasure company who ended up being bought by the very competitor I had reverse engineered.
But in the AI era, this strategy has become a trap.
When we reverse engineer a cited competitor, we are intentionally optimizing for the “average answer.”
When we do this, we are just adding more semantic noise instead of clear signal to the Knowledge Graph. By imitating a competitor who already has “Average Dominance,” you are telling the AI that you have nothing unique or a higher-fidelity to offer. You aren’t dislodging the authority; you are reinforcing their position as the “Consensus.”
The “Muddy” Web vs. The “Sharp” Domain Signal
When AI goes out to look for an answer during its autonomous discovery cycle it first determines the general consensus across the top 100 results to form a baseline and then the AI asks “why” related to the baseline answer. It is in this continuing discovery cycle that AI flies through the “average” noise to see if it can find a domain that explains the logic around it. AI is looking for a logic map. Understanding exactly how the AI searches for an answer through this cycle reveals why structural clarity matters more than content volume.
The problem is search is a legacy system. Most websites, even giant ones, are structurally fragmented, unconnected individual pieces of content without explicit semantic relationships surfaced in content and between articles . Their logic is buried under technical debt, shifting layouts, and inconsistent code.
AIs are known to be highly inconsistent when recommending brands
Spark Toro produced a study which asked the question of whether ChatGPT, Claude, or Google AI produced results that could be tracked to demonstrate some level of consistency to be able to track results. Study found that for ChatGPT it took 1429 exact query “rolls of the dice” to get a repeat of the exact list with the brands in the same order. For Google’s AI it required 124 to get the same brands, just not in the same order.
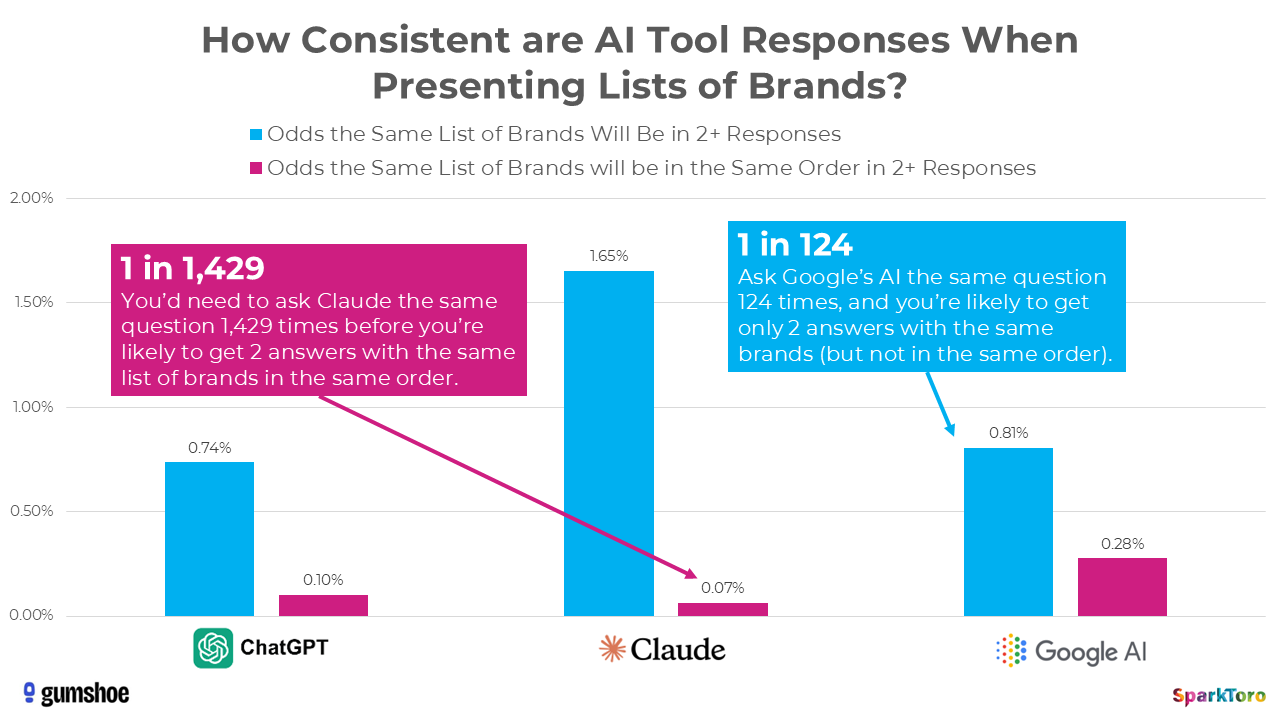
“The bottom line is: AIs do not give consistent lists of brand or product recommendations. If you don’t like an answer, or your brand doesn’t show up where you want it to, just ask a few more times.” [Spark Toro]
What I saw is empirical data to support a related conclusion that this is what it looks like when LLMs do NOT find the logic map they are hoping to find and choose to play it safe. There are many “safe answers.”
Why does the AI “Play it Safe”?
Because the “average answer” is based on a legacy system (pre-AI), when the AI searches for an answer and finds only “muddy signal” options, it defaults to the brand name it recognizes. It isn’t a vote for their logic; it’s a lack of confidence in everyone else.
The thing is, the AI is actually starving for the “sharp signal”, a logic map. It wants to cite a more precise, expert source, but it needs unambiguous proof before it can take the risk of moving away from the safe brand.
Forward Engineering From Consensus to Clarity
Instead of reverse engineering the competition which we see cited by LLMs, we should instead forward engineer the signal. Move beyond simple keyword matching and start building an explicit logic map on our own domains.
Creating a domain that has a firm topical center and connected together so it appears to an LLM to be its own knowledge graph would force AI to cite the domain.
The way to do this is to provide unambiguous “Knowledge Units” that the AI can digest with 100% confidence. This requires ensuring your logic is hard-coded, consistent, and structurally bounded.
When we give the AI the “Topical Structural Excuse” it needs to stop playing it safe. Our domains become the “Tie-Breaker” that allows the AI to choose expertise over an average consensus.
Winning the Answer Layer
The winner of the AI era isn’t the one who copies the most authority; it’s the one who provides the most Symmetrical Clarity across the html and the rendered dom.
Don’t work to be the alternative to the average answer. Give your site the architecture that makes the average answer obsolete.