

The 100% Indexation Breakthrough
For over a year I’ve been testing a simple structural ratio which yields 100% indexation rate. As an indexation nerd, I am compelled to make the distinction between indexed and served. They are two separate sub-systems in the Google Indexation System which internally Google refers to as Alexandria. (Yes, as in The Great Library of Alexandria from ancient times.)
There have been discussions around the benefit of a method of content creation called chunking, a process of breaking up a page of content into individual pages. I find the premise accurate, but that particular execution faulty.
There’s a way to use semantic HTML beyond making content accessible to readers for those with limited eyesight. What I found was a “pre-emptive chunking” strategy that aligns with the constraints of the legacy Google search index and modern Large Language Models (LLMs).
There is a heuristic structure that feels like magic.
The Evidence: Cracking the Indexation Threshold
In my daily indexation testing over the last 4 and half years, I started to notice a pattern in 2024. Creating 20 – 25 indexation test pages every month, tests with headers (H2, H3 etc) indexed easily and test content without these semantic headers did not.
But what had me perplexed was the data from some test content which contained H2 headers that did not index. Why?
Diving deeper into it I found that content which had a ratio of headers to word count of 10% indexed easily, while content with lower ratios was hit or miss and content significantly above 18% or higher – also did not perform.
The 10% ratio seemed to be a “Goldilocks Zone” for current indexation threshold.
Engineering Logic: Why 100 Words is a “Knowledge Unit
With this data in mind, it made clear to me why there were many anecdotal reports of content that was expected to be indexed and served but was not getting indexed.
Why is there a sweet spot?
Semantic Chunking for RAG and LLMs
Modern AI systems don’t just “read” a page; they “chunk” it. In Retrieval-Augmented Generation (RAG) architectures, a common default chunk size is often around 256 to 512 tokens (roughly 150–300 words). By providing a header every 100 words, we are performing pre-emptive chunking when we use our H2, H3, H4 etc headings. We’re actually addressing their Neural “attention span” because we understand the “attention decay” that occurs when a section is too long.
We are explicitly defining the boundaries where one concept ends and another begins, which reduces the “noise” the AI has to filter when creating vector embeddings.
The “Information Density” Threshold
Google’s legacy system relies on Document Understanding AI (like BERT and Smith). These models have limited “attention windows.” If a section is too long (e.g., 500 words under one H2), the semantic relationship between the header and the bottom of the text becomes weaker.
Conversely, if it’s too short (a header every 20 words), the content is flagged as “thin” or fragmented.
We curate trust through structural integrity. In the context of E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness), semantic hierarchy is a proxy for editorial intent. A document that follows a strict H1 > H2 > H3 structure with consistent section lengths signals that the content was curated by a human (or a sophisticated agent) for readability, rather than being a raw data dump.
This lowers the “perplexity” score of the document, making it “safer” for an AI to cite as a reliable source.
The Invisibility Penalty: Why Structure is the Key to AI Citation.
When you have 1,500 words under a single header, the AI creates one “vector” (a mathematical summary) for that entire block. Because the block covers too many topics, the vector becomes “muddy” or “diluted.” This will cause a retrieval failure.
When a user asks a specific question, the AI actively through the autonomous discovery cycle looks for “sharp” vectors that closely match the query. It will almost always choose a 100-word “Knowledge Unit” from a competitor over your 1,500-word “Mega-Block” because the competitor’s vector is mathematically more precise.
Even if your 1,500-word block contains the exact answer, the AI’s retrieval algorithm can’t “see” it through the noise of the surrounding 1,400 words. Content that isn’t structured correctly is effectively “invisible” for citation. It might be in the index, but it will never be the “Source” for an AI’s answer.
The Structural Bridge: Where Legacy Meets AI
This is structurally where Search and AI are served by this one thing.
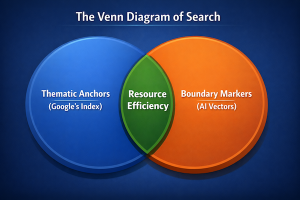
Search Side
For Google’s document understanding in its legacy systems, the headers act as Thematic Anchors. Google’s old-school “Caffeine” indexer and its BERT-based refinements aren’t “reading” the text like a human; they are performing Entity Extraction and N-gram analysis.
The 1:100 Header to Words Ratio provides just enough context for the algorithm to “weight” the surrounding 100 words. If a header covers 1,000 words, the signal-to-noise ratio drops, and the algorithm struggles to classify the primary intent of that section.
AI Side
For modern AI, our headers act as boundary markers for embeddings. When an AI “reads” a page to index it for a search like Perplexity or Gemini:
If we are performing pre-emptive chunking: The AI converts text into high-dimensional vectors (math). If you have a single H1 and 1,500 words of text, the “vector” for that entire block is “muddy” because it’s trying to represent too many concepts at once.
The 1:100 Header to Words Ratio: By breaking it into 15 headers, you are essentially “pre-sorting” the data into 15 distinct vector points. This makes it 100% easier for the AI to “retrieve” the exact right section when a user asks a specific question.
The “Dual-Purpose” Win
By using 10% header-to-content ratio, you are solving two different problems with one structural choice:
- For Google: You are reducing Categorization Entropy (making it easy to index).
- For AI: You are reducing Retrieval Latency and Hallucination Risk (making it easy to cite).
Scaling to the Local Knowledge Graph of The Domain
Ever wonder why “Mega-Posts” are losing to “Sharp-Vector” clusters when it comes to AI citation frequency?
The hub and spoke content structure is key. By limiting content length and interlinking into other content on the domain, you’re addressing two technical bottlenecks.
The “Context Window” Efficiency (Modern AI)
While LLMs like Gemini or GPT-4 have massive context windows, their retrieval accuracy (the “Needle In A Haystack” problem) often degrades as a single document gets longer.
- A 2000-word article: This keeps the entire document within a high-confidence retrieval range.
- The Interlinking: Instead of forcing one “Mega-Vector” for a 5000-word post, you are creating 3–5 “Sharp-Vectors” (the pillar + supporting posts). When an AI crawls these, it sees a linked data structure.
It can follow the links just like a human, but it’s also mapping the semantic proximity between those specific chunks of information.
The “Crawl Budget” and “Internal PageRank” (Legacy SEO)
Google’s “Caffeine” indexer loves the 1:100 ratio, but it also uses internal links to determine document importance.
- The Interlinking: By pointing multiple “100% indexed” supporting posts to a pillar post, this created a “gravity well” of topical authority. You’re telling the legacy indexer: “This pillar is the definitive source for this specific cluster of entities.”
- A 2000-word piece of content: This prevents indexed but not served in which Google indexes a page but doesn’t serve it because it couldn’t find a clear signal for it to know what to do with it.
The “Trust” Synergy: “Semantic Cohesion”
When an AI (or Google) observes 5 separate pages, all perfectly structured (1:100 ratio), all using enough words to convey meaning and depth, and all interlinked by semantic relationships, it calculates a high Semantic Cohesion score.
- It’s not just “trusting” one page; it’s trusting your entire site’s architectural intent.
- This is exactly how “Subject Matter Experts” are identified in the neural era: by their ability to break down complex topics into clear, interlinked, and logically structured units of knowledge.
- The Interlinking Strategy: Building topical authority by connecting perfectly structured, high-indexation posts.
- Semantic Cohesion: Shifting from “Page SEO” to “Architectural Intent”—telling the AI your entire site is a reliable node of knowledge.
Beyond the Header: Moving from the “What” to the “Where”
Are we utilizing the full value of semantic html by just using headers or can we take it another step?
Using additional HTML5 sectioning elements, we can further refine the mathematical scope of our headers by placing them in containers by using <article> and <section> tags and creating boundary confidence.
Defining and Creating “Boundary Confidence
An LLM or a legacy crawler uses headers as “entry points” for a chunk. And if we use <section> or <article> tags, we are providing Explicit Boundary Markers. Without <section>, the algorithm has to guess where a header’s influence ends. (Does this H2 apply to the next 100 words or the next 500?)
But with <section>: we can mathematically define the Scope of Relevance. This increases the “Confidence Score” for the AI when it extracts that specific chunk for a search result or a RAG (Retrieval-Augmented Generation) prompt.
The “Noisy” vs. “Clean” Data Problem
Modern AI indexers (like those used by Perplexity, OpenAI, or Google’s SGE) are trying to strip away “Boilerplate” (headers, footers, ads). Here’s what these other elements communicate.
- <article>: Tells the AI, “Everything inside here is the primary unique knowledge.”
- <aside>: Tells the AI, “This is related, but don’t weight it as heavily for the main topic.”
By using these, you are essentially “cleaning” the data for the AI before it even processes it. This reduces the “Computational Cost” for the AI to understand your page, which is a major factor in how “Trustworthy” a source is perceived to be.
The “Semantic Tree” vs. “Flat List”
When your only structure is Headers only it creates a “flat list” of topics. When you use semantic html including Headers AND Sectioning your content creates a hierarchical semantic tree.
For an AI, a tree is much easier to navigate than a list. It can “prune” irrelevant sections of the tree much faster, making your content more “efficient” to index and retrieve.
The Future is Structured
The 10% ratio is the “Structural Bridge” to the autonomous discovery cycle. In an era of AI-generated noise, the winner isn’t the one with the most content, but the one with the most retrievable content.